To help explain a bit more visually. *DISCLAIMER* this is all from memory, I haven't touched replication in a few years, so I could make some mistakes, but conceptually it should help you a lot.
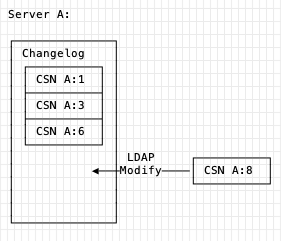
Each server when it accepts a change, add's the change with it's CSN to the change log - for a single server it looks like this.
Each server when it accepts a change, add's the change with it's CSN to the change log - for a single server it looks like this.
We add Server B now, and do a full re-init. The two servers then look like this:
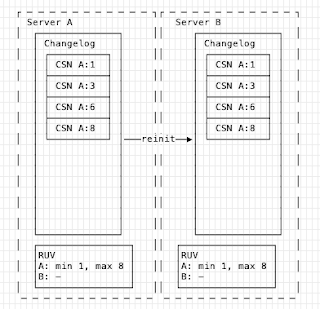
At this point we can also now see the RUV on each server. It shows the min/max CSN, relative to each *server* in the topology. Since we have no changes on B yet, it's empty.
Now we accept a change on B:
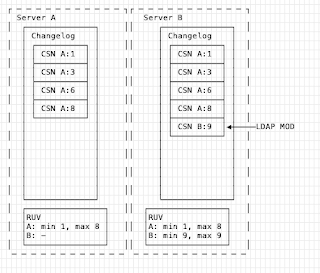
As you can see the RUV updates, and the changelog on B gets the new item. Replication hasn't happened yet, A has not yet perceived this change.
Similar, A now receives a change, and updates it's RUV.
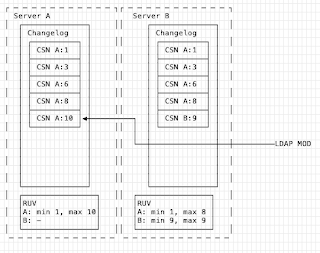
Next, B consumes from A (which supplies it's changes). The RUV's are compared and this shows that A has A:1 -> A:10, but B has A:1 -> A:8. This means A needs to supply changes A:9 -> A:10. There are no changes for B.
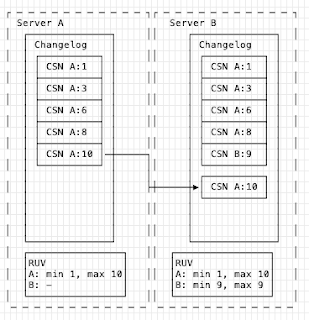
The supplied change is sorted into the changelog and then replayed to ensure that the operations are applied in the logical *time* order.
In reverse when B supplies to A, the RUVs are compared and A see's that it lacks the changes from B:
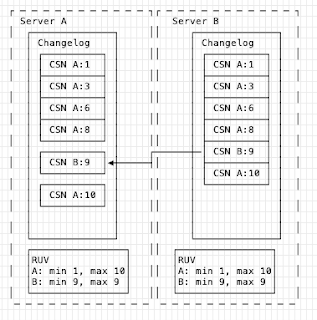
As we can see, A has to add change B:9 between A:8 and A:10 to ensure it has the same time order. The changelogs get replayed and then both servers apply the changes in the same order, bringing them both into the same state. In other words, replication has converged.
At some point, to save space, the changelogs are trimmed. If server B trimmed first:
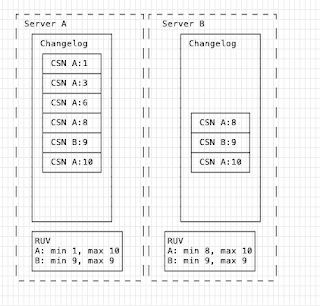
The key point here is a replica can be offline *only up to* the changelog trim window. The default is 7 days, so if a server was offline for 6 days and started up, it would still be possible for it to then re-sync and continue. If you had the following state:
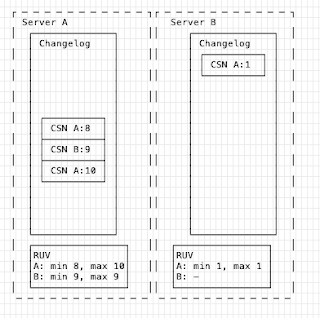
Replication here could not proceed - Server A has trimmed up to change A:8, while server B only has up to change A:1. This means that any changes between A:1 and A:8 "are not still present" in the changelogs, so replication can't proceed since data would be lost, as B can not replay and apply them.
This situation would necessitate a full re-init from A -> B to fix this.
Anyway, I hope this helps you understand a bit more about replication :)
> On 16 Nov 2023, at 06:14, David Boreham <david@bozemanpass.com> wrote:
>
>
> On Wed, Nov 15, 2023, at 12:02 PM, William Faulk wrote:
>> > it isn't necessary to keep track of a list of CSNs
>>
>> If it doesn't keep track of the CSNs, how does it know what data needs to be replicated?
>>
>> That is, imagine replica A, whose latest CSN is 48, talks to replica B, whose latest CSN is 40. Clearly replica A should send some data to replica B. But if it isn't keeping track of what data is associated with CSNs 41 through 48, how does it know what data to send?
>
> I said it doesn't track a _list_. It has the changes originating from each node, including itself, ordered by CSN, in the changelog. It asks peer servers it connects to what CSN they have seen, and sends the difference if any. Basically a reliable, in-order message delivery mechanism.
>
>>
>> > by asking the other node for its current ruv
>> > can determine which if any of the changes it has need to be propagated to the peer.
>>
>> In addition, the CSNs are apparently a timestamp and replica ID. So imagine a simple ring topology of replicas, A-B-C-D-E-(A), all in sync. Now imagine simultaneous changes on replicas A and C. C has a new CSN of, say, 100C, and it replicates that to B and D. At the same time, A replicates its new CSN of 100A to B and E. Now E has a new CSN. Is it
>> 100A or 101E?
>
> The CSNs have the property of globally order, meaning you can always compare two (e.g. 100A and 101E in your example) and come to a consistent conclusion about which is "after". All servers pick the one that's "after" as the eventual state of the entry (hence: eventually consistent). Note this is in the context of order theory, not the same as the time of day -- you don't have a guarantee that updates are ordered by wall clock time. You might have to look at the code to determine exactly how order is calculated -- it's usually done by comparing the time stamp first then doing a lexical compare on the node id in the case of a tie. Since node ids are unique this provides a consistent global order.
>
>>
>> If E's new max CSN is 100A, then when it checks with D, D has a latest CSN of 100C, which is greater than 100A, so the algorithm would seem to imply that there's nothing to replicate and the change that started at A doesn't get replicated to D.
>
> True, but iirc it doesn't work that way -- the code that propagates changes to another server is only concerned with sending changes the other server hasn't seen. It doesn't consider whether any of those changes might be superseded by other changes sent from other servers. At least that's the way it worked last time I was in this code. Might be different now.
>
>>
>> If E's max CSN is 101E, then, when D checks in with its 101D, it thinks it doesn't have anything to send. I suppose in this scenario that the data would get there coming from the other direction. But if E's max CSN is 101E, eventually it's going to check in with A, which has a max CSN of 100A, so it would think that it needed to replicate that same data back to A, but it's already there. This is an obvious infinite loop.
>
> No because see above the propagation scheme doesn't consider the vector timestamp (ruv), only the individual per-node timestamps (csn). Once a given change originating at some particular server has arrived at a server, no peer will send it again. You might have a race, but there is locking to handle that.
>
>>
>> I'm certain I'm missing something or misunderstanding something, but I don't understand what, and these details are what I'm trying to unravel.
>
> Understood. I've been through the same process many years ago, mainly by debugging/fixing the code and watching packet traces and logs.
>
>
>
>
> _______________________________________________
> 389-users mailing list -- 389-users@lists.fedoraproject.org
> To unsubscribe send an email to 389-users-leave@lists.fedoraproject.org
> Fedora Code of Conduct: https://docs.fedoraproject.org/en-US/project/code-of-conduct/
> List Guidelines: https://fedoraproject.org/wiki/Mailing_list_guidelines
> List Archives: https://lists.fedoraproject.org/archives/list/389-users@lists.fedoraproject.org
> Do not reply to spam, report it: https://pagure.io/fedora-infrastructure/new_issue
--
Sincerely,
William Brown
Senior Software Engineer,
Identity and Access Management
SUSE Labs, Australia
No comments:
Post a Comment